AI-driven school board documents search engine
A tool to help journalists search through hundreds of thousands of documents to find key issues in education.
For AP News
Technologies | PostgreSQL, NextJS, Vercel AI SDK, AWS, Serverless stack
View Project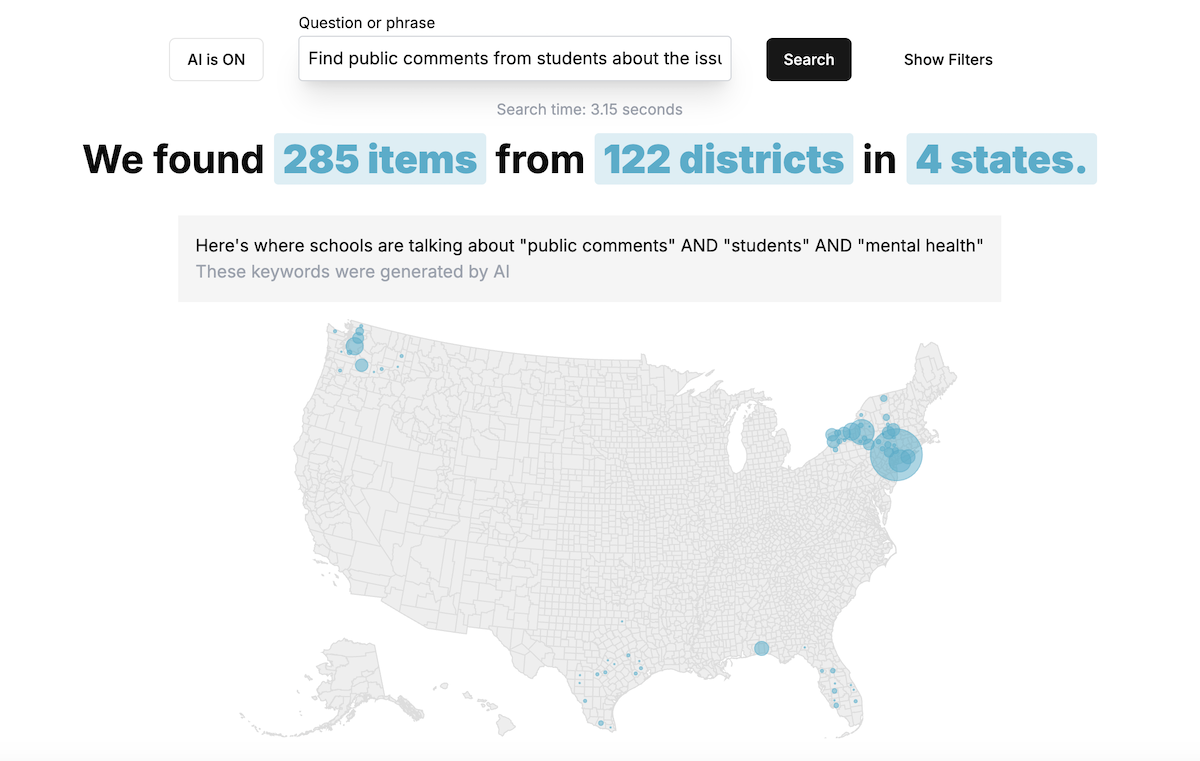
The problem
School board meeting agendas, district planning documents, and meeting transcripts reveal the most pressing issues for parents and students. An AP data journalist on the education team built a tool to scrape thousands of school board documents each month. They needed a developer to build a database and web app to help reporters search the documents and uncover trends. AP recently entered into a partnership with Open AI, so we were interested in exploring solutions that leveraged generative AI.

System Architecture and Design Approach
I was the only engineer working on this project, and needed to work within the budget of a nonprofit and time constraints of an active newsroom. AP uses AWS for cloud infrastructure, so I set up a postgreSQL database instance to store documents. I developed a NextJS web app, which allowed me to easily organize frontend and backend code and deploy to a serverless stack using SST. I set up automated deployments to continously update the app's lamba functions and static assets on S3 while keeping it functional for reporters.
Challenge: Keyword vs. Vector Search
A signficant consideration that I explored early on was the decision to use keyword search or vector search. Vector search offered the potential to type in questions and return context-sensitive results. However, it incurred large costs for storing vectors and embedding documents via the OpenAI API. I explored an alternative - using AI to generate keywords from an open-ended question and pass those into a Postgres full-text search. For this project, scale was a key consideration. We were scraping hundreds of thousands of documents, with plenty added each month. On the other hand, the app would have few monthly users as it was intended for journalists and small newsrooms, not the public at large. This meant that we needed to optimize for document storage, and could handle the tradeoff of more OpenAI calls for keyword-search queries in exchange for not having to use the embeddings API.

Challenge: Summarizing large documents
Many documents contained tens of pages of meeting information, which quickly exceeded the LLM's context window. To solve this problem, I implemented the map-reduce pattern. I first mapped large documents into smaller chunks, then made an API call to summarize each chunk. Then a final prompt instructed the AI to summarize all of the summaries.
Results
This is an ongoing effort. So far, nearly 45,000 documents are searchable. The education team uses the tool to find trends and publish stories on top issues.